
















By Karol Ilagan and Federico Acosta Rainis
Philippine Center for Investigative Journalism
Despite being known as “black boxes,” algorithms can still be examined by journalists. Here’s the behind-the-scenes of how we collected, analyzed, and reported on Grab’s surge pricing model.
Manila-based journalist Karol Ilagan is a regular customer of GrabCar, the ride-hailing app. In one of her trips to work in 2023, she paid a surge fee that was more than a third of the entire fare. It wasn’t the first time, but because she took the ride late morning on a slow Tuesday, she thought she was overcharged. She sent feedback to Grab Support and was told there was high demand, hence the higher fare.
Ilagan couldn’t challenge the “high demand” explanation because only Grab has access to the underlying data. Her experience, along with numerous stories on social media about Grab’s seemingly steep prices, and drivers’ complaints about their diminishing take-home pay, inspired this reporting project.
With support from the Pulitzer Center’s AI Accountability Network, she teamed up with data specialist Federico Acosta Rainis to test whether claims about Grab’s expensive rides could be proven systematically. Working with 20 researchers, we spent more than six months examining Grab’s algorithm and how it impacts consumers and drivers.
By collecting data from Grab and its online fare check tool, we discovered that rides for at least 10 routes always included surge charges, the fee added by Grab to get more cars on the road. Based on the app, there was always a higher demand than the cars available almost the entire day.
Knowing whether GrabCar rides always included surge fees was only the first thing we wanted to find out. We also wanted to check whether the ride-hailing company’s surge pricing model worked as advertised – that it would get more cars on the road. However, the data we gathered suggested that customers still had to endure lengthy wait times even when fares were high. We used wait times as a proxy for service quality.
Beyond the data, we also wanted to understand how Grab was able to dominate the market; how algorithms are regulated; the underlying factors that make navigating Metro Manila so difficult; and, perhaps most importantly, what needs to be done.
In the coming months, the Philippine Center for Investigative Journalism, PumaPodcast, and Commoner will be publishing stories about what we’ve found, including our data, and what the spatial unfixing of work means for Filipinos and how these intersect with systems of disadvantage. We’ll introduce you to drivers, riders, and commuters who often suffer the indignity of plying through the city streets every day. We’ll continue updating this page to share more about our process.
How we collected the data
To understand how Grab’s surge pricing model works, we collected one week’s worth of the company’s pricing information for 10 routes by gathering data from the app manually and through its online fare check tool.
App data: Manual collection
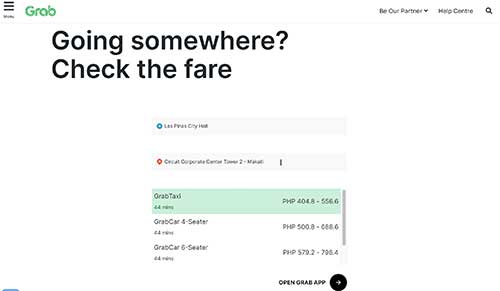
Ilagan formed a team of 20 researchers who attempted to book rides for 10 routes across Metro Manila every hour from 6 a.m. to midnight between Feb. 14 and Feb. 20, 2024. The last data collected was at 00:00 of Feb. 21, 2024. Taking shifts, two researchers were assigned for each route. We chose pick-up and drop-off locations across different cities in Metro Manila, including train stations, churches, hospitals, malls, universities, city halls, and the like.
The researchers attempted to book their assigned route at the top of the hour, i.e., 6 a.m., 7 a.m. and so on, to match the automated data collection led by Acosta Rainis (see below). At each booking attempt, they took screenshots of the booking page in the app with details on the fare for a GrabCar four-seater, estimated times of arrival to destination, and the suggested route.
After each booking attempt on the app, the researchers also took a screenshot on Google Maps with the route suggested by Google automatically. This was to register the time and distance recommended by Google because the app doesn’t show the distance.
If Google Maps’ default route wasn’t the same as the app’s, the researchers mimicked Grab’s route in Google Maps and took a second screenshot. It was necessary to mimic the route again to obtain the estimated trip distance, which was key to breaking down the fare.
A dry-run of this process was conducted by the researchers in January 2024 before the actual data collection took place in February 2024. Several rounds of data cleaning was conducted after the data collection.

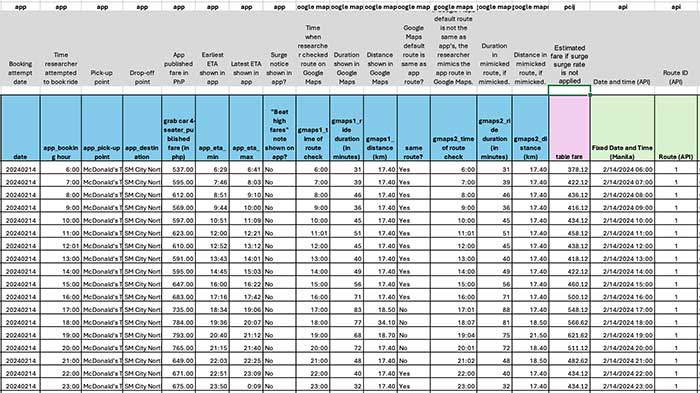
Acosta Rainis, who is based in Spain, meanwhile obtained data from Grab’s fare check application programming interface (API) every 15 minutes every day for the same routes during the same period.
On June 20, 2024, we found out that the online fare check tool was no longer available on Grab’s website. We asked the company about it but we have yet to get a response.
An API is a way for different software systems to talk to each other. It’s an intermediary that sets rules for different systems to exchange information. If we follow the rules, we can ask or “query” the API for the information we need from another system and it will go and fetch the information for us.
For our project, we used Grab’s Farefeed API, which allowed us to check fares for trips in real time by providing the start and end locations. There’s a private version for Grab’s partners, but we used the public version available on their website. As their API only provided one fare estimate at a time, we wrote a Python script to automate the process. We requested data from the API non-stop for a whole week, collecting 672 data points for each of the 10 trips.
Overall, we were able to collect 1,328 data points from the manual process and 6,720 through API. We decided to pursue both manual and API data collection to complement the built-in limitation from each method.
The API data, for example, showed only a range of fare estimates, while the app data showed the fixed rate that researchers would actually pay if they made the booking. On the other hand, querying the API every 15 minutes instead of every hour allowed us to get more data granularity.
Comparing these price points from two separate sources gave us confirmation that the data we were collecting were within similar ranges and not off the mark. Moreover, having different variables allowed us to analyze the data more comprehensively.
In any case, we do know that what we collected represented a small portion of Grab’s data, but it offered a glimpse into the inner workings of its algorithm.
How we analyzed the data
Our analysis began with a breakdown of the fares provided by the app using the fare matrix approved by the Land Transportation Franchising and Regulatory Board (LTFRB), the government body that regulates public transportation utilities. Here is the formula, as shown in a document from the Philippine Competition Commission. Note that the base fare now is P45, P15 per kilometer, and P2 per minute.

Below is a sample receipt:
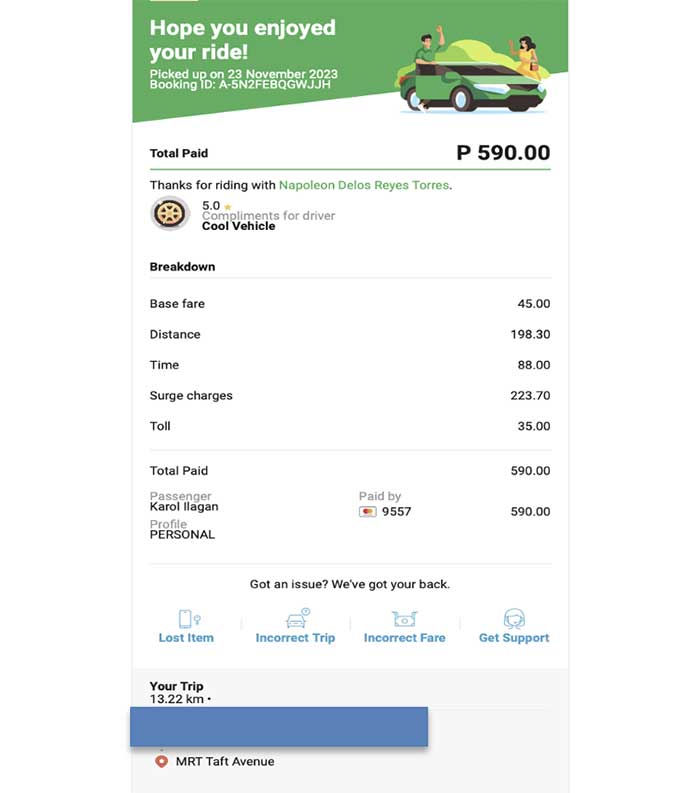
Using the LTFRB fare matrix, we can break down the fare above as follows:
Embed code:
Without surge charges, the trip would have cost: P45 plus P198.30 plus P88 = P331.30.
Following LTFRB’s fare matrix and Grab’s formula, the maximum surge charge can only reach up to twice the sum of P198.30 and P88 (P286.30*2) or P572.60. In this example, we calculated the surge multiplier as follows:
We get the sum of the distance and duration costs plus the surge fee applied.
P198.30 + P88 + P223.70 = P510
Then we divide the value above (P510) with the sum of the distance and duration costs to get the surge multiplier.
P510/P286.30 = 1.781
The surge multiplier is 1.78. The maximum allowed surge rate is x2.
We used the same formula to derive the fare components of each ride we attempted to book. Once the fares were broken down, we were able to conclude that there was always a surge rate applied, meaning there was always an amount left after subtracting the P45 base fare, P15 per kilometer, and P2 per minute rates set by the LTFRB.
Deriving the surge rate allowed us to explore and compare other variables such as its relationship with wait times, day, time of day, route, etc.
In addition to descriptive statistics, we also ran statistical analyses to further understand our data. We sought the help of several statisticians, including those from the School of Statistics at the University of the Philippines Diliman and De La Salle University Manila. While we were aware that we were not running scientific research that required more robust statistical analyses, we took this approach as a way to cover our bases. A common critique of reporting projects like ours is that data findings aren’t statistically significant.
According to the statistical results, the data did not show a significant correlation between surge rate and wait times. However, certain routes exhibited significant negative and positive correlation between these two variables.
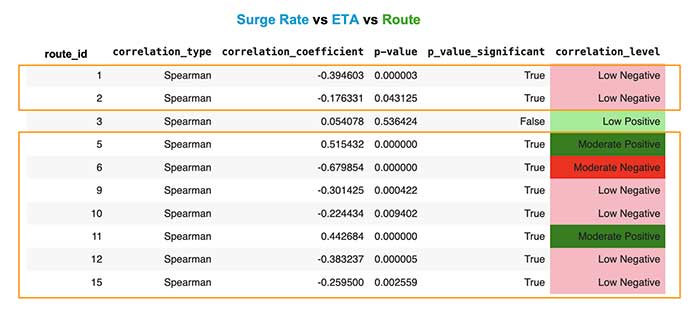
In the table above, surge pricing seemed to work best in Route 6 (moderate negative) and then somewhat work in Routes 1, 2, 9, 10, 12, and 15 (low negative). Route 6 is in Valenzuela, one of the less busy cities in Metro Manila.
Higher fares meanwhile did not correlate with shorter waiting times in Routes 5 and 11. Route 5 pick-up is Makati City, and Route 11, Taguig. These are business districts in Metro Manila.
How we reported the story
To really understand the impact of algorithm-based services to people, we learned from the experiences of at least a dozen commuters and 50 drivers and riders. Ilagan reached out to individuals who used GrabCar frequently. She also interviewed drivers and riders from several reporting trips to where they usually rest, such as Diokno Boulevard and Macapagal Avenue in Pasay City. Some of the interviewees requested anonymity for fear of retribution.
We read multiple transport studies on surge pricing to help inform the data collection process.
Ilagan also interviewed representatives from organizations monitoring ride-hailing companies and digital labor.
Ilagan tried to request data and interviews from the LTFRB, the Department of Trade and Industry’s Consumer Protection Group, the Department of Information and Communication Technology (DICT), and the PCC. Only DICT and PCC have responded as of posting time.
These interview requests focused on the role of the government as regulator, what the law, policy or rules and regulations say or do not say about algorithms, and Grab’s market dominance when it acquired Uber’s operations in the Philippines.
Our team
The story was reported by Pulitzer Center’s AI Accountability Network fellow Karol Ilagan and data specialist Federico Acosta Rainis.
Jabes Florian Lazaro contributed reporting and research for the article.
Data collection was done by Angelica Alcantara, Jay-ar Alombro, Donna Clarisse Blacer, Lyjah Tiffany Bonzo, James Kenneth Calzado, Gina de Castro, Maverick de Castro, Dominique Flores, Lois Garcia, Guinevere Latoza, Aya Mance, Faith Maniquis, Karmela Melgarejo, Gabriel Muñoz, Arone Jervin Ocampo, Matthew Raralio, Arriana Santos, and Angelica Ty.
Felipe Salvosa II was the lead editor.
Photographs were taken by Bernard Testa. Illustrations were created by Joseph Luigi Almuena.
Data visualizations were designed by Karol Ilagan, Federico Acosta Rainis, and Kuang Keng Kuek Ser.
This story was produced by the Philippine Center for Investigative Journalism in partnership with the Pulitzer Center’s AI Accountability Network.

